

Im ersten Teil ging es um Personen, Drama und drei Jahrzehnte Streit. In diesem Teil wird es technisch. Aber keine Sorge, ich verspreche dir, dass du am Ende nicht nur weisst, was Sample Rate und Latenz sind. Du wirst auch verstehen, warum dein Bluetooth Headset im Videocall plötzlich klingt, als würdest du in einen Eimer sprechen. Und das, ohne dass du auch nur eine einzige Konfigurationsdatei aufgemacht hast.
Wir bauen das in fünf Schritten auf. Erstens, was Audio überhaupt ist, also was im Innern einer Soundkarte passiert. Zweitens, der heutige Linux Audio Stack im Überblick. Drittens, das Vokabular, das du brauchst, um über alles weitere reden zu können. Viertens, das Graphenmodell von PipeWire, der eigentliche Paradigmenwechsel. Und fünftens, Bluetooth Audio als reales Problem, an dem alle Konzepte zusammenkommen.
Was eine Soundkarte eigentlich macht
Bevor wir über Server, Daemons und Stacks reden, müssen wir kurz darüber reden, was Audio im Computer überhaupt ist. Die Geschichte ist kurz, aber wer sie nicht kennt, kann den Rest nicht einordnen.
Schall ist eine kontinuierliche Welle. Dein Trommelfell wird von Luftdruckschwankungen ausgelenkt, dein Gehirn macht daraus Musik oder Sprache. Eine Soundkarte muss nun zwei Dinge können. Diese kontinuierliche Welle in eine Folge von Zahlen verwandeln, damit sie aufgenommen werden kann. Und umgekehrt, eine Folge von Zahlen wieder in eine kontinuierliche Welle verwandeln, damit der Lautsprecher sie ausspielen kann. Der erste Vorgang heisst Analog Digital Wandlung, der zweite Digital Analog Wandlung. Und genau hier kommen die zwei Begriffe ins Spiel, die du bei jeder Audio Konfiguration siehst.
Die Sample Rate ist die Frage, wie oft pro Sekunde gemessen wird. Bei 48000 Hertz, also 48 Kilohertz, wird die Schallwelle 48'000 Mal pro Sekunde abgetastet. Je öfter du misst, desto genauer kannst du hohe Frequenzen rekonstruieren. CD Qualität ist 44.1 Kilohertz, der heutige Standard auf Linux ist 48 Kilohertz, professionelle Studios arbeiten manchmal mit 96 oder 192 Kilohertz. Letzteres ist für die meisten Anwendungen Übertrieben, aber wir kommen gleich dazu, warum das trotzdem nicht egal ist.
Die Bit Tiefe ist die Frage, wie genau jede einzelne Messung ist. Bei 16 Bit hast du 65'536 mögliche Werte pro Sample, bei 24 Bit über 16 Millionen. Mehr Bits heisst mehr Dynamik, also mehr Abstand zwischen dem leisesten erkennbaren Ton und dem lautesten möglichen ohne Verzerrung. CDs sind 16 Bit, professionelle Aufnahmen 24 Bit, Studios arbeiten intern oft mit 32 Bit Floating Point.
Wenn du jetzt rechnest, kommst du auf erstaunliche Zahlen. 48000 Samples pro Sekunde, jedes 24 Bit, also 3 Byte gross, in Stereo macht das 288'000 Byte pro Sekunde, also rund 280 Kilobyte. Das mag wenig klingen, aber jetzt kommt der Haken. Diese Datenmenge muss kontinuierlich, unterbrechungsfrei und exakt im richtigen Tempo zur Soundkarte fliessen. Eine einzige Verzögerung von wenigen Millisekunden, und du hörst ein Knacksen oder einen Aussetzer.
Damit das funktioniert, gibt es den Buffer. Stell dir den Buffer als Eimer vor, in den die Anwendung Samples einfüllt und aus dem die Soundkarte Samples entnimmt. Solange der Eimer nicht leer wird, läuft alles glatt. Wird er leer, hörst du einen Aussetzer. Das ist der gefürchtete Underrun, im ALSA Sprech ein xrun. Genau dieses Knistern und Stottern, das Linux Audio jahrelang seinen Ruf gekostet hat.
Hier kommt der zentrale Trade Off, der den ganzen Stack durchzieht. Ein grosser Buffer ist sicher, aber langsam. Wenn der Eimer 100 Millisekunden Audio fasst, fällt eine Verzögerung von 50 Millisekunden gar nicht auf. Aber dafür hörst du jede Aktion in deinem System mit 100 Millisekunden Verzögerung. Beim Filmschauen ist das egal, beim Gitarrespielen ist es eine Katastrophe, weil dein Gehirn so etwas wie Latenz zwischen Anschlag und Ton nicht akzeptiert. Ein kleiner Buffer ist also genau umgekehrt. Niedrige Latenz, aber hohes Risiko von xruns, weil das System den Eimer ständig neu füllen muss, ohne ins Stottern zu geraten.
Diese Dynamik, Buffer Grösse gegen Latenz gegen CPU Last, ist das fundamentale Problem von Audio Software. Alles, was im Linux Audio Stack passiert, dreht sich letztlich um die Frage, wie man diesen Trade Off elegant löst.
Der Stack heute, von oben nach unten
Wenn du heute auf einem aktuellen Linux Desktop einen Ton abspielst, läuft das in fünf Schichten ab. Von oben nach unten.
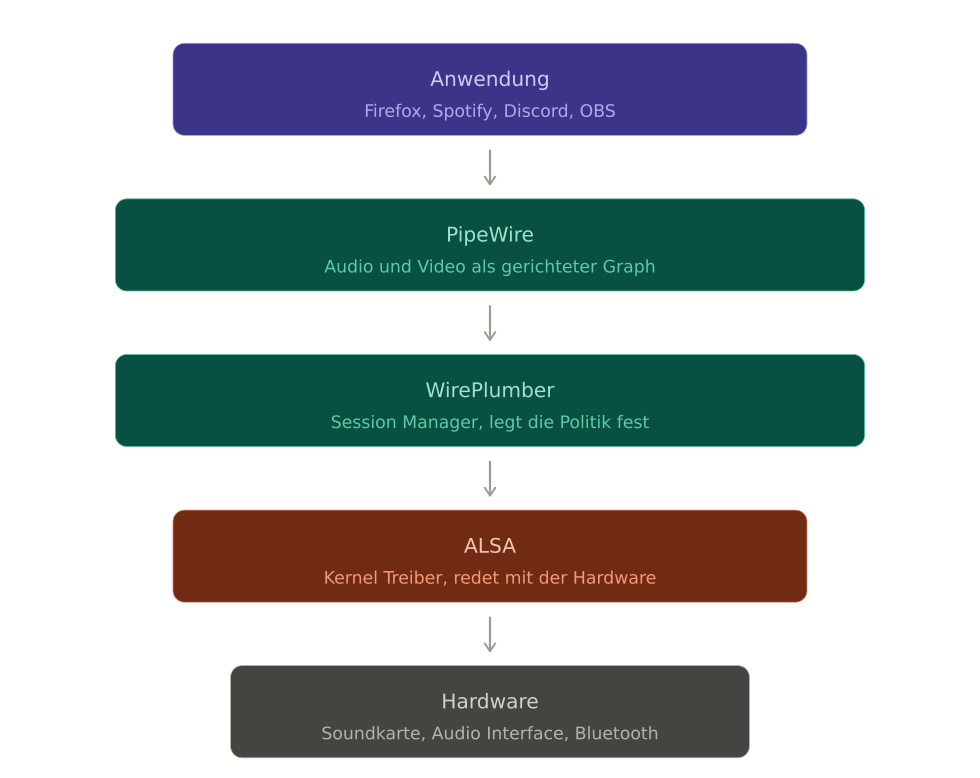
Ganz oben sitzt deine Anwendung. Firefox, der Musikplayer, das Videospiel, was auch immer. Diese Anwendung will Audio ausgeben und ruft dafür eine API auf. Das kann die PulseAudio API sein, die JACK API, das ALSA API, oder das native PipeWire API. Hier ist der erste wichtige Punkt. Die Anwendung muss heute nicht mehr wissen, was unter ihr läuft. Sie redet einfach in einer dieser vier Sprachen, und der Rest des Stacks kümmert sich darum.
Eine Schicht darunter sitzt PipeWire. Es nimmt die Audio Daten der Anwendung entgegen, egal über welche der vier APIs sie kommen. Intern hat PipeWire nur eine einzige Vorstellung davon, wie Audio aussieht, nämlich als Datenfluss in einem Graphen. Was die Anwendung in PulseAudio Sprache geschickt hat, wird intern zu einem Knoten im PipeWire Graphen. Was eine andere Anwendung in JACK Sprache geschickt hat, wird zu einem zweiten Knoten. PipeWire kann beide gleichzeitig handhaben, ohne dass eine die andere blockiert. Das ist der Punkt, an dem dreissig Jahre Stackchaos zusammenfallen.
Eine Schicht darunter sitzt der Session Manager, in der Praxis fast immer WirePlumber. PipeWire selbst kümmert sich nur um den Datenfluss, also um den Pfad der Samples vom Sender zum Empfänger. Aber wer entscheidet, welche Soundkarte das Default Gerät ist? Welche Lautstärke gerade aktiv ist? Was passiert, wenn du ein Headset einsteckst? Diese Politik Fragen, also Was soll wann mit was verbunden werden, beantwortet WirePlumber. Du kannst dir PipeWire als die Bahn vorstellen und WirePlumber als den Fahrplan.
Noch eine Schicht darunter sitzt ALSA. ALSA ist heute nicht mehr der Soundserver, aber es ist immer noch die Kernel Schnittstelle. Die ALSA Treiber im Linux Kernel sprechen direkt mit der Hardware und stellen ihre Funktionen über ein einheitliches Interface zur Verfügung. PipeWire benutzt diese Treiber, um die Samples letztlich an die Soundkarte zu schicken. Es gibt im modernen Stack nur noch sehr wenige Anwendungen, die ALSA direkt ansprechen, ohne PipeWire dazwischen. Ein klassisches Beispiel ist alsamixer für die reine Hardware Konfiguration einer Soundkarte.
Und ganz unten sitzt die Hardware. Die Soundkarte selbst, sei es der eingebaute Audio Chip in deinem Laptop oder ein USB Audio Interface. Sie nimmt die digitalen Samples und macht daraus analogen Strom für deine Lautsprecher.
Wenn du das einmal verinnerlicht hast, wird vieles klar. Wenn jemand sagt, er habe ein PulseAudio Problem, dann redet er in Wahrheit fast immer mit PipeWire, das nur so tut, als wäre es PulseAudio. Wenn jemand alsamixer öffnet, redet er nicht mit PipeWire, sondern direkt mit der Hardware Schicht darunter. Und wenn dein Bluetooth Headset komische Profile hat, ist das WirePlumber, das die Politik festlegt.
Das Vokabular, das du brauchst
Vier Begriffe begegnen dir überall, sobald du dich mit Linux Audio beschäftigst. Sie kommen aus PulseAudio, sie haben in PipeWire überlebt, und sie sind nicht so kompliziert, wie sie klingen.
Ein Sink ist ein Ziel für Audio. Dein Lautsprecher ist ein Sink. Dein Kopfhörer ist ein Sink. Eine virtuelle Aufnahme Spur in OBS ist auch ein Sink. Wenn etwas Audio entgegen nimmt, ist es ein Sink. Übersetzt heisst das Wort schlicht Senke, also der Ort, wo etwas hinfliesst.
Eine Source ist genau das Gegenteil. Eine Quelle. Dein Mikrofon ist eine Source. Der "Line In" deiner Soundkarte ist eine Source. Aber auch ein Audio Stream, den eine andere Anwendung gerade aufnimmt, ist aus deren Sicht eine Source. Wenn etwas Audio produziert, ist es eine Source.
Eine Node ist die abstrakte Form von beidem. Im Graphenmodell von PipeWire ist alles eine Node. Dein Lautsprecher ist eine Node. Dein Mikrofon ist eine Node. Firefox ist eine Node. Spotify ist eine Node. Ein Effekt wie ein Equalizer ist eine Node. Manche Nodes haben nur Eingänge, manche nur Ausgänge, manche beides.
Ein Link ist eine Verbindung zwischen zwei Nodes. Wenn Spotify gerade über deinen Lautsprecher spielt, gibt es einen Link zwischen der Spotify Node und der Lautsprecher Node. Wenn du gleichzeitig mit Discord redest, gibt es einen weiteren Link zwischen der Discord Node und dem Lautsprecher und einen vom Mikrofon zur Discord Node.
Damit hast du das Vokabular, um über alles zu reden, was im Stack passiert. Jetzt kommt der Teil, der wirklich neu ist.
Der Paradigmenwechsel von PipeWire
PulseAudio dachte in Strömen, die zwischen Quellen und Senken fliessen. Du hattest deine Anwendung, sie schickte ihren Strom an einen Sink, fertig. Das war eine signifikante Verbesserung gegenüber dem Chaos davor, aber es war fundamental linear gedacht.
PipeWire dachte das anders. Es behandelt das gesamte Audio System als gerichteten Graphen, also als Netzwerk von Nodes, die durch Links verbunden sind. Das ist genau das Modell, das JACK schon Jahre vorher für Profis benutzt hatte. Und genau hier liegt der Geniestreich von Wim Taymans, von dem ich in Teil 1 gesprochen habe. Er hat das Profi Modell genommen und zum Default für alle gemacht, ohne dass die Anwendungen davon wissen müssen.
Was bedeutet das konkret. Wenn du heute Spotify hörst und gleichzeitig in Discord sprichst, sieht der Graph etwa so aus. Spotify Node, mit einem Link zur Lautsprecher Node. Mikrofon Node, mit einem Link zur Discord Node. Discord Node, mit einem Link zur Lautsprecher Node.Vier Nodes, drei Links, ein Graph.
Jetzt willst du vielleicht etwas Ungewöhnliches. Du willst, dass die Audio Ausgabe von Spotify auch an OBS geht, damit du sie streamen kannst, aber ohne dass deine Discord Stimme im Stream landet. In PulseAudio war das eine umständliche Frickelei mit virtuellen Sinks und Loopbacks. In PipeWire klickst du in einer Patchbay Software einen weiteren Link von Spotify zur OBS Node, und fertig. Dasselbe Audio Signal kann beliebig oft abgegriffen werden.
Du kannst Effekte als Nodes einfügen. Ein Equalizer wird zu einer Node, die Audio entgegen nimmt, transformiert und weitergibt. Du legst einen Link von deinem Mikrofon zur Equalizer Node und einen weiteren von der Equalizer Node zur Discord Node. Plötzlich klingt deine Stimme in jedem Programm besser, ohne dass irgendein Programm wissen muss, dass es einen Equalizer gibt.
Diese Art zu denken, ist der Grund, warum Linux heute Audio Setups erlaubt, die unter Windows oder macOS nur mit Spezialsoftware oder gar nicht möglich sind.
In Teil 3 zeige ich dir, wie du diesen Graphen mit Tools wie qpwgraph sichtbar machst und manipulierst. Aber das Modell selbst musst du jetzt schon im Kopf haben.
Latenz, das ungeliebte Mass aller Dinge
Bevor wir zu Bluetooth kommen, brauchen wir noch ein letztes Konzept. Latenz, also die Zeit, die Audio braucht, um durch den Stack zu wandern. Latenz misst sich in Millisekunden, und sie ist nicht abstrakt, sondern wird auf verschiedenen Ebenen aufgebaut.
Da ist erstens die Hardware Latenz. Jede Soundkarte hat eine eingebaute Verzögerung, weil die Wandlung zwischen Analog und Digital Zeit braucht. Bei guten USB Audio Interfaces sind das wenige Millisekunden, bei billigen Onboard Chips können es zehn oder mehr sein.
Zweitens die Buffer Latenz. Wir haben oben gesehen, dass ein grösserer Buffer mehr Sicherheit gegen xruns gibt, aber dafür mehr Verzögerung verursacht. Wenn dein Buffer 1'024 Samples gross ist und du mit 48 Kilohertz arbeitest, fügt das allein 21 Millisekunden hinzu. Bei 64 Samples sind es nur 1.3 Millisekunden, aber dafür musst du eine sehr saubere Konfiguration haben.
Drittens die Verarbeitungslatenz im Stack selbst. PipeWire arbeitet intern in Quanten, also festen Zeitscheiben, in denen es Daten von einer Node zur nächsten schiebt. Wie gross dieses Quantum ist, hängt von der Konfiguration ab. Für normales Desktop Audio ist es grob, etwa 1'024 Samples. Für Pro Audio kann es auf 64 oder gar 32 Samples runter, was extrem niedrige Latenz erlaubt, aber das System stark fordert.
Die Gesamtlatenz, die du am Ende wahrnimmst, ist die Summe aus all diesen Schritten. Bei einem normalen Linux Desktop liegst du irgendwo zwischen 30 und 60 Millisekunden, was für alles ausser Pro Audio völlig in Ordnung ist. Mit gutem Setup kommst du unter 5 Millisekunden, was für Musikproduktion ausreicht. Ein Mac liegt im selben Bereich, aber mit weniger Möglichkeiten zur Anpassung. Windows ist standardmässig schlechter, weil es keine vergleichbare Realtime Architektur hat, ausser du benutzt Spezialtreiber wie ASIO.
Warum Bluetooth Audio das härteste Problem im ganzen Stack ist
Jetzt setzen wir das alles zusammen. Bluetooth Audio ist das perfekte Beispiel, weil hier alle Konzepte gleichzeitig auftreten und sich gegenseitig in den Weg geraten.
Bluetooth war ursprünglich nicht für hochwertiges Audio gedacht. Es entstand für Maus, Tastatur und einfache Datenübertragung. Audio kam später dazu, und zwar in zwei sehr unterschiedlichen Profilen, die bis heute überleben.
Das eine Profil heisst A2DP, was für Advanced Audio Distribution Profile steht. Es ist für Musik gedacht, also Stereo, hohe Qualität, aber nur in eine Richtung. Vom Computer zum Kopfhörer, nicht zurück. A2DP überträgt Audio in einem von mehreren Codecs, und genau hier wird es interessant. SBC ist der Standard Codec, den jedes Bluetooth Gerät kann, klingt aber durchschnittlich. AAC ist besser, vor allem auf Apple Geräten, aber nicht überall verfügbar. aptX gehört Qualcomm und braucht spezielle Hardware. LDAC kommt von Sony und liefert die beste Qualität, aber nicht jedes Gerät unterstützt es. PipeWire hat in den letzten Jahren erstaunlich gute Codec Unterstützung dazugewonnen, was vorher unter PulseAudio teilweise eine Katastrophe war.
Das andere Profil heisst HSP oder HFP, also Headset Profile beziehungsweise Hands Free Profile. Es ist für Telefonie gedacht. Stereo gibt es nicht, denn Telefonate sind Mono. Hohe Qualität gibt es auch nicht, denn die Bandbreite muss reichen, um gleichzeitig Audio in beide Richtungen zu schicken, also Mikrofon und Lautsprecher gleichzeitig. Das Resultat ist ein Codec mit acht Kilohertz Sample Rate, was etwa der Qualität eines Festnetztelefons aus den Achtzigern entspricht.
Es gibt einen verbesserten Codec namens mSBC mit 16 Kilohertz, aber auch das ist weit entfernt von dem, was du gewohnt bist.
Hier kommt der Schock. Diese beiden Profile, A2DP und HSP, schliessen sich gegenseitig aus. Bluetooth kann nicht beides gleichzeitig. Wenn du Musik hörst, läuft A2DP. Sobald du eine Anwendung benutzt, die ein Mikrofon verlangt, also Discord, Zoom, Teams oder ein Browser Tab mit Videocall, muss der Stack auf HSP umschalten. Das ist der Moment, in dem deine Musik plötzlich klingt, als käme sie aus einem Eimer. Sie kommt jetzt nämlich nur noch in Mono mit niedriger Sample Rate bei dir an.
Das ist nicht Linux spezifisch, das ist eine Eigenschaft des Bluetooth Standards. Aber Linux hat dieses Problem länger gehabt als andere Betriebssysteme, weil PulseAudio mit den Codec Verhandlungen oft schlecht klar kam. Heute, unter PipeWire mit WirePlumber, läuft das wesentlich besser. Trotzdem gibt es Momente, in denen WirePlumber sich entscheiden muss, und du kannst diese Entscheidung in der Politik des Session Managers anpassen, etwa damit dein Headset bei einem Videocall im A2DP Modus bleibt und du das Mikrofon deines Laptops benutzt.
Wenn du in Teil 3 sehen wirst, wie man WirePlumber konfiguriert, wird dir das vertraut vorkommen. Du wirst dem Session Manager sagen, welche Politik er für welches Gerät verfolgen soll. Das ist genau die Art von Eingriff, für die der Stack gebaut ist.
Was du jetzt verstanden hast
Du weisst, was Sample Rate, Bit Tiefe und Buffer sind und warum sie miteinander einen Trade Off bilden. Du kennst den Linux Audio Stack von oben nach unten, also Anwendung, PipeWire, WirePlumber, ALSA, Hardware. Du verstehst das Vokabular von Sinks, Sources, Nodes und Links und weisst, dass das Graphenmodell von PipeWire der eigentliche Paradigmenwechsel war.
Du hast eine Vorstellung davon, wie Latenz zustande kommt und an welchen Schrauben man drehen kann. Und du weisst, warum dein Bluetooth Headset im Videocall bescheiden klingt, und dass das nicht die Schuld von Linux ist, sondern die Schuld eines Standards aus den späten Neunzigern.
Im nächsten Teil: Wir gehen vom Verstehen zum Anfassen. Welche Tools brauchst du wirklich, welche kannst du getrost ignorieren, und welches sind die ein, zwei Geheimwaffen, von denen kaum jemand redet, obwohl sie alles ändern? Ich zeige dir die Kommandozeilen Werkzeuge wie wpctl und pw-top, die grafischen Patchbays wie qpwgraph, und vor allem EasyEffects, das wahrscheinlich nützlichste Stück Audio Software, das je für Linux geschrieben wurde.
Teil 3 kann hier gelesen werden.
