

Bild von erfouris studio auf Pixabay
Stell dir vor, du schreibst in Thunderbird eine E-Mail, merkst dass der Ton etwas zu grob geraten ist, markierst den Absatz, drückst Super+F und zack - der Text in deiner Zwischenablage ist freundlicher formuliert. Kein Tab-Wechsel, kein ChatGPT, keine Daten die irgendwohin gehen. Alles passiert auf deiner Maschine. Das gleiche Kürzel funktioniert in Signal, in VS Code, in LibreOffice, im Browser. Egal wo du Text hast, ein Druck und er wird umgeschrieben.
In diesem Artikel richten wir genau das ein. Wir nutzen dafür die neuen Inference Snaps aus Ubuntu 26.04, das Sprachmodell Gemma 3 von Google und etwa 60 Zeilen Bash. Das Ganze läuft auf deiner CPU, auf deiner integrierten Grafik, auf deiner NVIDIA-Karte oder auf der NPU in deinem neuen Intel-Laptop - der Snap entscheidet selber, was am schnellsten ist. Am Ende hast du einen Workflow, den du nie mehr hergeben willst. Versprochen.
Was sind Inference Snaps und warum sind sie ein Gamechanger
Wer lokal KI laufen lassen wollte, kannte bisher den Schmerz: Welche Quantisierung für meine GPU? Läuft CUDA oder brauche ich ROCm? Wie viel VRAM habe ich eigentlich? Nimmt man llama.cpp, Ollama oder doch vLLM? Und jede Runtime will anders konfiguriert sein.
Canonical hat seit Oktober 2025 zusammen mit Intel, Ampere und weiteren Chip-Herstellern eine neue Art von Snap-Paket eingeführt: den Inference Snap. Die Idee ist simpel und brillant: Ein Snap pro Modell, der bei der Installation deine Hardware erkennt und dann genau die passende Runtime plus die passenden Modellgewichte herunterlädt. Kein Raten, kein Basteln.
Konkret heisst das:
- Ein Befehl reicht:
sudo snap install gemma3und das Modell läuft. - Automatische Hardwareerkennung: CPU, Intel-GPU, Intel-NPU oder NVIDIA-GPU werden erkannt, die beste Engine wird gewählt.
- OpenAI-kompatible API: Der Snap startet einen lokalen Server mit genau derselben API, die auch OpenAI nutzt. Jede Software, die du bisher mit OpenAI verbunden hast, spricht ohne Anpassung mit Gemma.
- Komplett offline: Nach dem Download brauchst du keine Internetverbindung mehr.
- Aktualisierungen: Wie bei jedem Snap rollen Updates automatisch rein.
Neben gemma3 gibt es auch deepseek-r1, qwen-vl und nemotron-3-nano. Für unseren Use Case reicht Gemma 3 locker.
Schritt 1: Treiber installieren
Wir machen das bewusst vor der Snap-Installation. Grund: Der Inference Snap prüft beim ersten Start, welche Hardware er nutzen kann. Sind die Treiber schon da, wählt er automatisch die beste Engine. Installierst du den Treiber erst danach, musst du die Auswahl manuell neu anstossen (mit sudo gemma3 use-engine --auto). Der Weg über "Treiber zuerst" erspart dir diesen Schritt.
Welchen Abschnitt du brauchst, hängt von deiner Maschine ab - schau nach und überspring die anderen.
Intel NPU: Die kleine Rechen-Kiste in neueren Laptops
Wenn du dir in den letzten zwei Jahren einen Laptop mit Intel Core Ultra gekauft hast - also genau die Geräte, die Microsoft als Copilot+ PCs bewirbt - hast du eine NPU an Bord. Das ist ein dedizierter Chip für KI-Aufgaben, stromsparend und richtig flott. Ubuntu stellt den passenden Userspace-Treiber als Snap bereit:
sudo snap install intel-npu-driverDas war es. Kein Kompilieren, keine Kernel-Module, nichts. Reboot ist nicht nötig.
Für Intel-GPUs (sowohl integrierte wie Arc-Karten) brauchst du meistens nichts zu tun - die User-Space-Treiber sind direkt im Inference Snap enthalten.
NVIDIA CUDA: Für alle mit einer Nvidia Karte
Die Inference Snaps nutzen CUDA 12 und brauchen mindestens Treiberversion 525. Prüfen:
apt list --installed nvidia-driver*sudo apt update
sudo ubuntu-drivers install
sudo rebootubuntu-drivers install wählt automatisch den passenden Treiber für deine Karte. Danach einmal neu starten.
AMD ROCm: Für die Radeon-Fraktion
Seit Ubuntu 26.04 liegt ROCm offiziell in den Paketquellen (Universe). Das ist eine grosse Neuerung, früher musste man sich durch AMDs eigenes Repository hangeln. Jetzt reicht:
sudo apt update
sudo apt install rocmDein Benutzer muss in den Gruppen render und video sein:
sudo usermod -aG render,video $USERRechner neustarten, damit die Gruppenmitgliedschaft greift und die Treiber geladen werden. Gut zu wissen: Die Inference Snaps haben aktuell ihren Fokus auf Intel und NVIDIA. Bei AMD läuft Gemma trotzdem - über die CPU-Engine oder per Vulkan-Fallback - aber die volle ROCm-Beschleunigung kommt peu à peu dazu. Für unseren Clipboard-Rewriter reicht CPU-Inferenz auf jedem halbwegs modernen Ryzen problemlos.
Schritt 2: Gemma installieren und testen
Jetzt wird es ernst:
sudo snap install gemma3Der Snap checkt deine Hardware, lädt die passende Engine plus Modelle und richtet einen systemd-Service ein. Das dauert beim ersten Mal ein paar Minuten - ein paar Gigabyte wollen runtergeladen werden.
gemma3 statusDu siehst dort die gewählte Engine (z.B. intel-npu-amd64, nvidia-gpu-amd64 oder cpu-amd64) und den Endpoint - bei mir läuft der Server auf http://localhost:8328. Den Port merkst du dir, gleich brauchen wir ihn.
gemma3 use-engine --autoNun können wir mit curl einen kurzer Test machen und prüfen ob das Modell funktioniert. Wir fragen Ihn einfach "Hallo, funktionierst du?":
curl -sS http://localhost:8328/v3/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gemma-3-4b-it",
"messages": [{"role": "user", "content": "Hallo, funktionierst du?"}]
}' | jq -r '.choices[0].message.content'Wenn Gemma dir antwortet, ist alles bereit. Falls nicht: gemma3 status zeigt, ob der Service läuft, und sudo journalctl -u snap.gemma3.server -e zeigt die Logs.
curl -s http://localhost:8328/v3/models | jq -r '.data[].id'Je nach gewählter Engine ist das etwas wie gemma-3-4b-it-ov-int4-fq (Intel/OpenVINO) oder gemma-3-4b-it (CPU/CUDA). Diesen Namen müssen wir uns merken wir brauchen den gleich im Script.
Schritt 3: Das Herzstück - der Clipboard-Rewriter
Jetzt bauen wir das eigentliche Werkzeug. Es soll:
- Den aktuell markierten oder kopierten Text aus der Zwischenablage lesen
- Ihn an Gemma schicken, zusammen mit einer Anweisung ("schreib freundlicher", "kürzer", "auf Englisch")
- Die Antwort zurück in die Zwischenablage legen
- Eine Notification anzeigen
Voraussetzungen:
sudo apt install wl-clipboard jq libnotify-binwl-clipboard liefert wl-copy und wl-paste für Wayland (das ist in Ubuntu 26.04 Standard). Falls du noch auf X11 bist, nutze stattdessen xclip - die Logik bleibt gleich.
Jetzt erstellst du das Script unter ~/.local/bin/ai-rewrite:
#!/usr/bin/env bash
set -euo pipefail
MODE="${1:-friendly}"
ENDPOINT="http://localhost:8328/v3/chat/completions"
MODEL="gemma-3-4b-it-ov-int4-fq"
case "$MODE" in
friendly)
SYSTEM="Schreibe den Text freundlicher und wärmer um, behalte aber Bedeutung und Länge bei. Gib NUR den umformulierten Text zurück, ohne Kommentar."
;;
shorter)
SYSTEM="Kürze den Text auf das Wesentliche, ohne wichtige Informationen zu verlieren. Gib NUR den gekürzten Text zurück, ohne Kommentar."
;;
english)
SYSTEM="Übersetze den Text ins Englische. Gib NUR die Übersetzung zurück, ohne Kommentar."
;;
fix)
SYSTEM="Korrigiere Tippfehler und Grammatik im Text. Der Ton und Stil bleiben gleich. Gib NUR den korrigierten Text zurück, ohne Kommentar."
;;
bullets)
SYSTEM="Forme den Text in eine saubere Bulletpoint-Liste um. Gib NUR die Liste zurück, ohne Kommentar."
;;
*)
notify-send "ai-rewrite" "Unbekannter Modus: $MODE"
exit 1
;;
esac
INPUT="$(wl-paste)"
if [[ -z "${INPUT// }" ]]; then
notify-send "ai-rewrite" "Zwischenablage ist leer"
exit 0
fi
notify-send -t 2000 "ai-rewrite" "Verarbeite... ($MODE)"
PAYLOAD="$(jq -n \
--arg model "$MODEL" \
--arg sys "$SYSTEM" \
--arg user "$INPUT" \
'{
model: $model,
temperature: 0.3,
messages: [
{role: "system", content: $sys},
{role: "user", content: $user}
]
}')"
RESPONSE="$(curl -sS -X POST "$ENDPOINT" \
-H "Content-Type: application/json" \
-d "$PAYLOAD" \
| jq -r '.choices[0].message.content')"
if [[ -z "$RESPONSE" || "$RESPONSE" == "null" ]]; then
notify-send -u critical "ai-rewrite" "Keine Antwort vom Modell"
exit 1
fi
printf '%s' "$RESPONSE" | wl-copy
notify-send -t 3000 "ai-rewrite" "Fertig: $(echo "$RESPONSE" | head -c 60)..."Stelle sicher, dass ~/.local/bin in deinem $PATH ist (bei Ubuntu seit Jahren Standard).
bin in .local neu erstellen musstest, melde dich am Desktop kurz ab- und wieder an, damit er in den $PATH aufgenommen wird.Und passe die MODEL-Zeile und den Port im Script an, falls dein Snap einen anderen Namen serviert (siehe Ausgabe von curl -s http://localhost:8328/v3/models | jq -r '.data[].id') .
Schneller Test
Bevor wir Hotkeys belegen, probieren wir das Script von Hand:
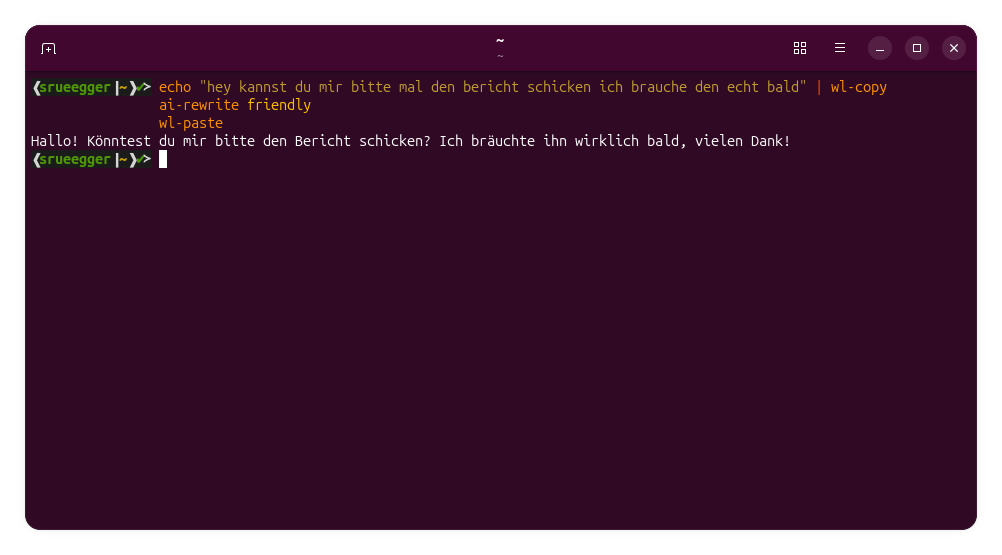
echo "hey kannst du mir bitte mal den bericht schicken ich brauche den echt bald" | wl-copy
ai-rewrite friendly
wl-pasteDie Ausgabe sollte etwa so klingen:
Hallo, könntest du mir bitte bei Gelegenheit den Bericht zusenden? Ich bräuchte ihn zeitnah. Vielen Dank!
Probier auch mal ai-rewrite english mit einem deutschen Text oder ai-rewrite bullets mit einem zusammengewürfelten Absatz.
Schritt 4: Globale Hotkeys in GNOME einrichten
Jetzt das Sahnehäubchen. Wir binden das Script an Tastenkürzel, die überall in deiner Session funktionieren.
Öffne Einstellungen → Tastatur → Tastenkombinationen anzeigen und anpassen → Eigene Tastenkombinationen.
Klick auf + und leg folgende Shortcuts an:
AI: Freundlich
- Befehl:
/home/DEINNAME/.local/bin/ai-rewrite friendly - Tastenkombination:
Super+F
AI: Kürzer
- Befehl:
/home/DEINNAME/.local/bin/ai-rewrite shorter - Tastenkombination:
Super+K
AI: Englisch
- Befehl:
/home/DEINNAME/.local/bin/ai-rewrite english - Tastenkombination:
Super+E
AI: Korrektur
- Befehl:
/home/DEINNAME/.local/bin/ai-rewrite fix - Tastenkombination:
Super+R
DEINNAME jeweils mit deinem Benutzernamen. Die Tastenkombination kannst du natürlich frei wählen.Ideen zum Weiterspinnen
Der Rewriter ist nur der Anfang. Mit derselben Architektur kannst du bauen:
- Git-Commit-Generator:
git diff --cached | ai-rewrite commitgibt eine saubere Commit-Message. - Screenshot Dateiname: Kombinier das Qwen-VL Snap mit einem Hotkey, der dir ein Screenshot anahand vom Inhalt direkt umbennent.
- Slash-Commands in Thunderbird: Ein kleines Add-on, das
/summaryoder/replymit dem lokalen Modell auflöst.
Das Schöne an der Inference-Snap-Architektur: Der Port, die API und das Format sind immer gleich. Was du einmal gebaut hast, funktioniert mit jedem neuen Modell, das Canonical in den Snap Store stellt.
Andere Modelle: Gemma ist nur der Anfang
Gemma 3 ist ein guter Allrounder, aber vielleicht brauchst du etwas Spezielleres. Canonical pflegt bereits eine ganze Familie von Inference Snaps, und alle funktionieren gleich - gleicher OpenAI-kompatibler Endpoint, gleiches status-Kommando, gleiche Hardware-Erkennung:
deepseek-r1: Das Reasoning-Modell aus China, stark bei Mathematik, Logik und Code. Installation:sudo snap install deepseek-r1.qwen-vl: Ein Vision-Language-Modell von Alibaba. Kann Bilder verstehen - praktisch für OCR-Aufgaben, Screenshot-Beschreibungen oder Alt-Texte.nemotron-3-nano: Ein kompakteres Modell von NVIDIA, schlank und schnell auch auf bescheidener Hardware.
Den Rewriter auf ein anderes Modell umzustellen ist eine Zwei-Zeilen-Änderung: Port und Modellnamen anpassen, fertig. Jeder Snap läuft auf seinem eigenen Port (deepseek-r1 status verrät ihn), parallel zu allen anderen.
Und falls dir Snaps grundsätzlich nicht zusagen: Ollama ist die etabliertere Alternative aus der breiteren Linux-Community. Gleiche Idee (lokales Modell mit OpenAI-kompatibler API), läuft aber als klassischer Dienst statt als Snap und hat einen grösseren Katalog an Modellen. Dein ai-rewrite-Script läuft mit Ollama genauso, du änderst lediglich Endpoint (http://localhost:11434/v1/chat/completions) und Modellnamen. Ich persönlich mag die Inference Snaps wegen der Hardware-Auto-Detection und der Integration ins System, aber Ollama ist für reine CLI-Menschen genauso valide.
Fazit
Lokale KI war lange ein Bastelprojekt mit Kernelmodulen, Python-Virtualenvs und VRAM-Kopfzerbrechen. Mit Ubuntu 26.04 und den Inference Snaps ist es ein Einzeiler. Und sobald das Modell läuft, reicht ein bisschen Bash, um daraus echte tägliche Werkzeuge zu bauen - die deine Daten auf deinem Gerät lassen.
Das hier ist der Moment, auf den Linux-Desktop-User gewartet haben: KI, die du besitzt, nicht mietest. Wenn du die vier Shortcuts eine Woche lang nutzt, wirst du dich fragen, wie du ohne ausgekommen bist.
Viel Spass beim kreativ sein mit KI.
